 A French corpus of audio and multimodal interactions in a health smart home
A French corpus of audio and multimodal interactions in a health smart home

Important Notice
These data have been acquired in the context of a PhD. thesis, in a laboratory that work on Health Smart Home. These databases, devoted to activity recognition and distress recognition, are distributed free of charge, for an academic and research use only, in order to be able to compare the results obtained. By downloading these anonymous data, you agree to the following limitations:
- Commercial use: This database is not designed for any commercial use and should only be used for academic researchers.
- Publications: Any publication using the activity database should include a citation of the article: Fleury, A.; Vacher, M. and Noury, N.; « SVM-Based Multi-Modal Classification of Activities of Daily Living in Health Smart Homes: Sensors, Algorithms and First Experimental Results ». IEEE Transactions on Information Technology in Biomedicine, Vol. 14(2), March 2010, pp. 274-283 (DOI:10.1109/TITB.2009.2037317). In the same way, all the publications that use the
- Redistribution: This database cannot be, totally or partially, further distributed, published, copied or disseminated, in any way or form, for profit or not.
- In the same way, all the publications that use the distress call dataset must include a reference to the following book chapter: Vacher, M., Fleury, A., Portet, F., Serignat, J.F., Noury, N.: “New Developments in Biomedical Engineering, chap. Complete Sound and Speech Recognition System for Health Smart Homes: Application to the Recognition of Activities of Daily Living“, pp. 645 – 673. Intech Book (2010).
For all questions or concerns, do not hesitate to contact us by email: anthony.fleury@mines-douai.fr
Information on these datasets concerning their contents and their way to be indexed etc. can also be found in the article: Fleury, A.; Vacher, M.; Portet, F.; Chahuara, P. and Noury, N.: “A french corpus of audio and multimodal interactions in a health smart home” . Journal on Multimodal User Interfaces, Springer Berlin / Heidelberg, 2012, 17p (DOI:10.1007/s12193-012-0104-x).
A copy of this website may be found Here.
Context of the acquisitions
The following presented acquisitions were made during a PhD Thesis, in the Health Smart Home of the TIMC-IMAG Laboratory (UMR CNRS 5525), Team AFIRM (that is now part of the AGIM Laboratory,FRE 3405, CNRS-UJF-EPHE). The PhD thesis were advised by Norbert Noury (TIMC-IMAG, now member of INL Laboratory in Lyon), and Michel Vacher (LIG Laboratory, Team GETALP).
Presentation of the Smart Home of the TIMC-IMAG Laboratory
The smart home of the TIMC-IMAG lab is a flat containing a kitchen, a living room, a bedroom, a bathroom, a hall and toilets. This flat is completely equipped and contains all the materiels that can be used for the different activities in the home (including books, clothes, TV, radio, microwave oven, fridge, food, etc.).
It is also equipped of several sensors as microphones, presence infra-red sensors, and webcams. It also contains a temperature and hygrometry sensor that is inside the bathroom, and the dweller is equipped with an home-made accelerometer and magnetometer circuit that is placed under the left armpit.
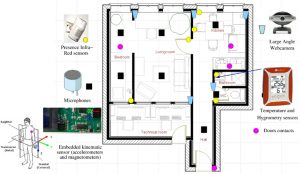
Finally, all the data are stored on different computers that are placed in the technical room, just next the flat.
Data Sets
Distress call dataset
Experimental protocol
The protocol was quite simple. Each participant was alone in the flat. The participant had to go to the living room and to close the door. Then, s/he had to move to the bedroom and read aloud the first half of one of the five successions of sentences, out of 10 normal and 20 distress sentences. Afterwards, the second half of the set of sentences had to be uttered in the living room. Finally, each participant was called 3 times and had to answer the phone and read the predefined phone conversation (5 sentences each). The sentences were uttered in the flat, with the participant sat down or stood up. They have no orders on the way they orient themselves comparing to the microphones or on the way they pronounced the different sentences.
Dataset content and organization
This dataset has been acquired on 10 different subjects. The main informations on the different subject are given in the following table (in this experiment, all the subject were native French speakers).
| ID | Age | Gender | Weight (kg) | Height (m) | Speech Number |
| 1 | 61 | M | 82 | 1,7 | 1 |
| 2 | 22 | M | 77 | 1,77 | 2 |
| 3 | 53 | M | 67 | 1,68 | 3 |
| 4 | 47 | M | 56 | 1,7 | 4 |
| 5 | 31 | M | 62 | 1,7 | 5 |
| 6 | 25 | M | 78 | 1,84 | 2 |
| 7 | 51 | F | 64 | 1,65 | 4 |
| 8 | 29 | F | 53 | 1,6 | 3 |
| 9 | 28 | F | 61 | 1,69 | 1 |
| 10 | 25 | M | 90 | 1,88 | 5 |
For each subject, the last column of the table gives the sequence number of the different sentences that have been pronounced. Indeed, we had 5 different sequences of sentences (with normal, distress and phone conversations). The different sequences can be found in an Excel file, by consulting the appropriate sheet (corresponding to the given number).
On the server, the dataset is organized as follow:
- A directory containing the complete dataset for each subject. This full dataset contains ALL the sounds that have been captured during the different sessions. For each subject, we can find:
- 8 directories that correspond to the different channels,
- For each channel, the different files that correspond to each acquisition (the most important are first the wave file that contains the acquired sound and the xml file that give the analysis of this sound by our system, with its segmentation as sound or speech and if sound, the classification in one of the sound classes and if speech the five more probable sentences that fit this sound).
- With these 8 directories, a text file (named Resultats.txt), that contains a first analysis with the following information: for sound, the SNR, the ID of corresponding wav/xml files, and the class of the sound), and for speech, the SNR, the ID of the xml/wav files, and the three first most probable sentences that have been determined by the system.
- A directory, containing for each speaker, only the files that correspond to the sounds with the best SNR, for only each of the sentences that have been uttered during the experimentation (all the other sounds have been deleted). The order of the sentences is kept comparing to the XLS spreadsheet given before.
- A directory containing all the sounds (and associated) files that correspond to the best SNR and to all the sounds with an SNR upper that 80% of this first value. In the same way than before, the order of the sentences is kept and the XML files contains the timestamps and the identification of all the simultaneous sounds, allowing to determine which sound correspond to which sentence.
More information on the experiment, on the datasets and on the process are given in the references [Vacher2008, Vacher2010, Vacher2011].
Data
| ID | Whole Set | RSB Max | 80 % |
| 1 | Zip File (19 Mo) |
Zip File (2,1 Mo) |
Zip File (5 Mo) |
| 2 | Zip File (22 Mo) |
Zip File (2,2 Mo) |
Zip File (4,9 Mo) |
| 3 | Zip File (21 Mo) |
Zip File (2,1 Mo) |
Zip File (5,3 Mo) |
| 4 | Zip File (22 Mo) |
Zip File (2,2 Mo) |
Zip File (5 Mo) |
| 5 | Zip File (20 Mo) |
Zip File (2,1 Mo) |
Zip File (4,6 Mo) |
| 6 | Zip File (32 Mo) |
Zip File (2,1 Mo) |
Zip File (4,9 Mo) |
| 7 | Zip File (32 Mo) |
Zip File (2,2 Mo) |
Zip File (4,2 Mo) |
| 8 | Zip File (27 Mo) |
Zip File (1,7 Mo) |
Zip File (3,6 Mo) |
| 9 | Zip File (21 Mo) |
Zip File (2,1 Mo) |
Zip File (4,4 Mo) |
| 10 | Zip File (19 Mo) |
Zip File (1,8 Mo) |
Zip File (3,3 Mo) |
| All | Zip File (231 Mo) |
Zip file (21 Mo) |
Zip file (45 Mo) |
Activities of Daily Living dataset
Experimental protocol
The experimental protocol was quite simple. The first step of the experimentation was a deep visit of the flat, to allow the person to act as much as possible as if s/he was home. After this visit, the only requirement to the subject was to perform a set of 7 activities, in the order and for the duration that s/he wanted, and as many times as s/he wanted.
The list of activities to perform was:
- Sleeping: you lie in the bed and stay “asleep” for a reasonable time (of your choice)
- Resting: you sit on the couch or a chair in the living room and perform the activity that you like when you are relaxing (watching TV, reading, doing nothing…)
- Feeding: you prepare a breakfast with the equipment and the ingredients in the kitchen cupboard and then eat (using the kitchen table). Then, you wash the dishes in the kitchen sink.
- Hygiene: you wash your hands, face, and pretend to brush your teeth in the bathroom.
- Toilets: you pretend to go (or you do) to the bathroom (sit on the toilet, flush the toilet…).
- Dressing: you put and remove the clothes in the chest of drawers near the bed (over your own clothes). You can do this activity before going to sleep and after sleep or after performing the hygiene task.
- Communication: you will be called over the phone (in the living room) several times. Each time you will read the sentences indicated near the phone (one long phone conversation and three small ones).
For more information about the dataset and the experiments, feel free to consult the references [Fleury2010, Fleury2011, Vacher2011, Noury2011].
Dataset content, organization and downloading
The data of 2 of the subjects are for the moment made available on this web page.
To retrieve the complete dataset including all the participants, please fill-in the PDF form and sent it to Anthony.Fleury@mines-douai.fr to engage yourself to use this dataset in a correct way. When done, you will receive the link to download the remain participants of the dataset.
The subjects have the following information:
| ID | Age | Gender | Height (m) | Weight (kgs) | Phone conversations ID | Native French Speaker ? |
| 1 | 25 | F | 1.77 | 63 | 1 | yes |
| 2 | 25 | F | 1.78 | 70 | 2 | yes |
| 3 | 32 | M | 1.92 | 80 | 3 | yes |
| 4 | 57 | F | 1.48 | 50 | 4 | no |
| 5 | 25 | M | 1.72 | 81 | 5 | yes |
| 6 | 26 | M | 1.82 | 66 | 1 | no |
| 7 | 28 | M | 1.78 | 68 | 2 | yes |
| 8 | 31 | M | 1.7 | 63 | 3 | yes |
| 9 | 26 | M | 1.84 | 78 | 4 | yes |
| 10 | 24 | F | 1.62 | 68 | 5 | no |
| 11 | 29 | F | 1.63 | 57 | 1 | yes |
| 12 | 40 | F | 1.76 | 60 | 2 | yes |
| 13 | 33 | M | 1.75 | 79 | 3 | no |
| 14 | 34 | M | 1.85 | 76 | 4 | yes |
| 15 | 43 | M | 1.72 | 69 | 5 | yes |
The phone conversations can be retrieved as an Excel File.
Dataset Download
In this section, you will be able to download partially or completely the dataset for each of the two participants. The different data that you can retrieve from this section will be detailed in the following sections.
To retrieve the complete dataset including all the participants, please fill-in the PDF form and sent it to Anthony.Fleury@mines-douai.fr to engage yourself to use this dataset in a correct way. When done, you will receive the link to download the remain participants of the dataset.
All the data are available as Gzip files, that you can unzip with almost every archive software (Winzip, winrar, 7-zip, etc.).
| ID | Video file (section 2) | Indexation files (section 3) | Audio Data (section 4) | Actimetry Raw Data (section 5) | Sensors (sections 6-8) |
Complete Data Set |
| 2 | 02_video.tar.gz (719 Mo) | 02_annotations.tar.gz (6,3 ko) | 02_son.tar.gz (46 Mo) | 02_actim6d.tar.gz (4,1 Mo) | 02_sensors.tar.gz (36 ko) | 02_all.tar.gz (768 Mo) |
| 9 | 09_video.tar.gz (528 Mo) | 09_annotations.tar.gz (5,8 ko) | 09_son.tar.gz (38 Mo) | 09_actim6d.tar.gz (2,8 Mo) | 09_sensors.tar.gz (35 ko) | 09_all.tar.gz (568 Mo) |


These compressed videos are from 4 different cameras and are all compressed in MPEG 4 (Xvid codec). They have been mixed into one only video, that show the kitchen on the top left, the kitchen/hall/bathroom door on the bottom left, bedroom and living room on the top right and finally the living room only on the bottom right. On the previous both images, the left one is Subject 2 and the right one subject 9 in the experiment.
One detail about the toilets and bathroom. As we can not (ethically speaking) put video camera in this room, it has been decided that when entering this part of the flat, if the dwellers want to go in the bathroom part, s/he close partially the door if s/he wants to go to the bathroom (hygiene activity) and totally if s/he aims to go to the toilets.
These large videos files can be downloaded in the Video column of Section 1.
Activity Indexation
An XML file is given to annotate the different activities that have been performed by the dweller during the experimental session.
This file contains first an information that allow to synchronize the Actimetry Sensor (ACTIM6D) to the other data. Indeed, all the data are synchronized because all the clocks of the different computers used to make the different acquisition are synchronized to the same NTP server. For this first information, the position correspond to the given date in the ACTIM6D_Synchro section of the XML file.
The second information are the real information of this dataset, that is to say the Activities of Daily Living that are performed by the dweller during the experimental session. For each activity, two timestamps are given: The beginning of the activity (named in French “debut”, and the end (in French “fin”). In the Activite, the id correspond to the activity that has been annotated. The different activities are:
| ID | Activity |
| 1 | Sleeping |
| 2 | Resting (TV, read, radio, …) |
| 3 | Dressing/Undressing |
| 4 | Eating |
| 5 | Toilet use |
| 6 | Hygiene |
| 7 | Communication |
In addition to this file, an Advene annotation file is provided and contains:
- The ground truth annotation for activity (as the previous file but with file position instead of timestamp)
- The ground truth annotation for posture (for some of the subjects, see section 5)
- The ground truth annotation for the uses of the house furnishings (see section 8)
The XML files can be found in the “Indexation Files” part of the section 1. The first file is named Y.xml and the Advene file is named AdveneAnnotation_Y.xml, with Y the ID of the subject.
Audio Data
As previously presented, audio data are separated with each directory containing the files of a specific microphone, and a text files that sums up the results of the classification of each sound that occurs in the flat. All the data are given in one Zip file that contains all the needed files.
Actimetry Data
ACTIM6D is a home made circuit board that contains a 3 axis accelerometer and a 3 axis magnetometer. It is fixed under the left armpit of the subject, in a pocket of a specific t-shirt.
The data that we recover from it are the three values of the acceletometers and the three values of the magnetomters. They are then used to detect the postural transitions of the subject and the walking status.
On this page, the raw data are given so that users can implement or use their own algorithm to detect the postural transitions (that can be annotated using the video). The file contains the following information on each line:
- The number of the experiment (an integer from the flash memory of the card)
- The second in which the recording has been made
- The value of the Accelerometer on X axis (see the previous figure for the axis orientations) (in hexadecimal)
- The value of the Accelerometer on Y axis (in hexadecimal)
- The value of the Accelerometer on Z axis (in hexadecimal)
- The value of the Magnetometer on X axis (in hexadecimal)
- The value of the Magnetometer on Y axis (in hexadecimal)
- The value of the Magnetometer on Z axis (in hexadecimal)
- The value of the temperature sensing of the board (decimal)
For more details about this sensor and the way to process these data, feel free to consult [Fleury2009].
Presence Infra-Red Sensors Data
At each detected movement in one of the rooms of the flat, the presence infra-red sensors fire a detection that is logged into a text file. This file contains, for each detection:
- The date of this occurrence (format DD/MM/YYYY)
- The hour of the occurrence (format HH:MM:SS)
- The room in which the detection occurred (that fit with one of the previously introduced detector).
This text file can be found in the Sensor part of section 1, with a name format HIS_Y.txt with Y the ID of the subject.
Hygrometry and Temperature Data
The bathroom contains a device that gives, every 5 minutes, the temperature and hygrometry in the room. For this sensor, a simple text files give the different information with the following format:
- A column containing the timestamp (format DD.MM.YYYY-HH:MM)
- The value of the temperature (in celcius degree)
- The value of the hygrometry (in %).
This text file can be found in the Sensor column of section 1, under the name Tempature.temp_Y.txt (with Y the ID of the Subject).
Chest of Drawers, Fridge and Cupboard use data
We finally put some sensors that allow us to know when some of the furnitures of the flat were used. There are three ones : the chest of drawers, the fridge and the cupboard (containing all the materials to prepare the meals).
These text files only notify the changes in the state of the door of the concern furniture. It is organized as follows:
- The timestamp (format DD-MM-YYYY-HH-MM-SS)
- The new state (Zero for close, One for open)
These files can be downloaded in the Sensor part of Section 1. Three text files are present in the Sensor archive, one named Cupboard_Y.txt, a second named Drawers_Y.txt and a third Fridge_Y.txt, where Y is the ID of the subject.
References
- [Fleury2013] A French corpus of audio and multimodal interactions in a health smart home. Anthony Fleury, Michel Vacher, François Portet, Pedro Chahuara, Norbert NouryJournal on Multimodal User Interfaces, Springer, 2013, 7 (1), pp.93-109
Distress Call Dataset
- [Vacher2008] Vacher, M.; Fleury, A.; Serignat, J.-F.; Noury, N. et Glasson, H.; « Preliminary Evaluation of speech/sound recognition for telemedicine application in a real environment » in Interspeech’08, Brisbane, Australia, 2008, pp. 496-499. [pdf]
- [Vacher2010] Vacher, M.; Fleury, A.; Portet, F.; Serignat, J.-F. and Noury, N.; « Complete Sound and Speech Recognition System for Health Smart Homes: Application to the Recognition of Activities of Daily Living », in New Developments in Biomedical Engineering, ISBN: 978-953-7619-57-2, pp. 645 – 673, 2010. [pdf]
- [Vacher2011] Vacher, M., Portet, F.; Fleury, A.; Noury, N.; « Development of Audio Sensing Technology for Ambient Assisted Living: Applications and Challenges ». International Journal of E-Health and Medical Communications, 2(1):35-54, mar 2011. [pdf]
Activity of Daily Living Dataset
- [Fleury2009] Fleury, A. ; Noury, N. et Vacher, M. ; « A wavelet-based pattern recognition algorithm to classify postural transitions in humans », in proc. EUSIPCO2009, 17th European Signal processing Conference, Glasgow, Scotland, Aug. 24-28, 2009, pp.2047-51. [pdf]
- [Fleury2010] Fleury, A.; Vacher, M. et Noury, N.; « SVM-Based Multi-Modal Classification of Activities of Daily Living in Health Smart Homes : Sensors, Algorithms and First Experimental Results ». IEEE Transactions on Information Technology in Biomedicine, Vol. 14(2), March 2010, pp. 274-283 (DOI:10.1109/TITB.2009.2037317). [pdf]
- [Fleury2011] Fleury, A.; Noury, N.; Vacher, M.; « Improving Supervised Classification of Activities of Daily Living Using Prior Knowledge ». International Journal of E-Health and Medical Communications, 2(1):17 – 34, mar 2011. [pdf]
- [Noury2011] Noury, N.; Poujaud, J.; Fleury, A.; Nocua, R.; Haddidi, T. et Rumeau, P.; « Smart Sweet Home… a pervasive environment for sensing our daily activity?», in « Activity Recognition in Pervasive Intelligent Environments », Series Atlantis Ambient and Pervasive Intelligence, Pub. Atlantis Press, Eds. L. Chen, C. Nugent, J. Biswas, J. Hoey, vol. 4 (2011), 328 p., ISBN: 978-90-78677-42-0. [pdf]
- [Chahuara2012] Chahuara, P.; Fleury, A.; Portet, F. et Vacher, M.; « Using Markov Logic Network for On-line Activity Recognition from Non-Visual Home Automation Sensors », in Lecture Note in Computer Sciences vol. 7683, Paterno, F. ; Ruyter, B. ; Markopoulos, P. ; Santoro, C. ; Loenen, E. ; Luyten, K. ed., pp. 177-192, 2012. [pdf]